
21 фев. 2024
1 мин
15

Меня зовут Илья, я ведущий менеджер подразделения Технического сопровождения проектов. Наша команда обеспечивает круглосуточный мониторинг и стабильную работу IT-инфраструктур клиентов.
Мы решаем задачи любой сложности. Один из таких примеров — данный кейс по повышению отказоустойчивости. Решение уже успешно работает у клиента под нашим сопровождением. Далее о том, с какой проблемой обратился клиент и к чему мы пришли в итоге.
Клиент попросил не раскрывать его данные — по соображениям безопасности. Скажу только, что его инфраструктура обрабатывает большие объёмы данных, а недоступность даже одного сервиса может привести к полному простою всего проекта.
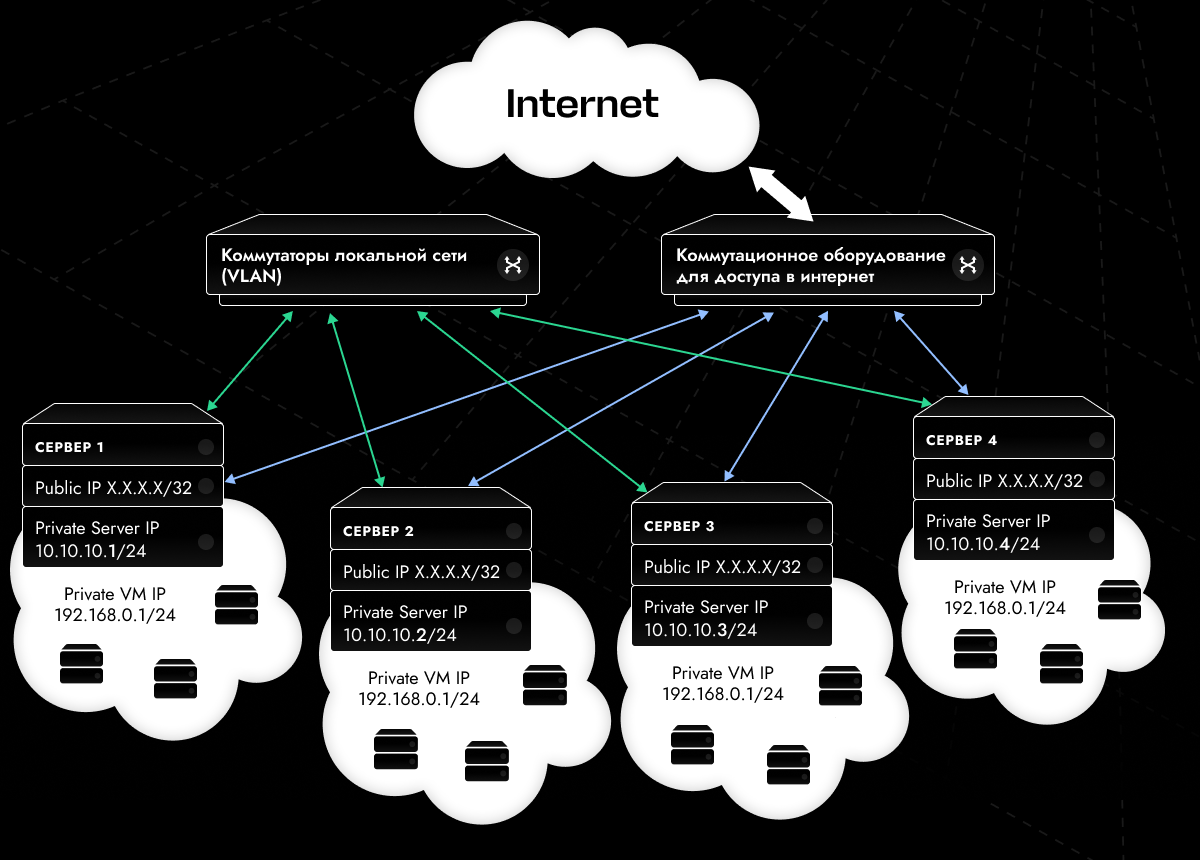
Чтобы сложилась общая картина, немного поясню. На базе нашего хостинга у клиента развернут кластер из 4 серверов под управлением системы виртуализации Proxmox. Всего в кластере работает около 200 виртуальных машин, которые используются под разные сервисы и задачи.
Клиент обратился к нам с задачей повысить отказоустойчивость сервисов, отвечающих за фронтенд. Цель — минимизировать возможные простои в случае сбоев на уровне физических хостов.
Основная идея состояла в том, чтобы дублировать сервисы фронтенда, которые занимаются приемом и ранжированием трафика. Такая возможность уже была заложена клиентом на уровне архитектуры проекта. При этом он поставил важное ограничение: для каждого сервиса нужно использовать только определенные IP-адреса — один и тот же IP на основной и резервной ВМ. То есть при сбое дубль сервиса должен быть доступен по тому же адресу, что и основной.
Самый подходящий инструмент для решения такой задачи — использование плавающих IP-адресов.
Плавающий IP (Floating IP) — это динамически назначаемый сетевой идентификатор, который может автоматически изменяться системой при определённых условиях или по мере необходимости. Отличается от статического IP тем, что не привязан жестко к конкретному узлу и может быть переадресован другому оборудованию или интерфейсу в зависимости от заданных параметров и текущего состояния сети.
Использование плавающих IP-адресов позволило бы решить задачу клиента — сохранять за сервисом его IP-адрес, даже при смене ВМ, на которой он размещен. Проще говоря, если ВМ с сервисом выходит из строя, IP-адрес этого сервиса автоматически начинает работать на резервной виртуальной машине. Сервис остается доступен. Переключение IP-адреса происходит менее чем за 3 секунды.
Вроде бы все отлично — бери и делай. Но есть проблема.
На нашем хостинге нет услуги плавающих IP. Дизайн сетевой архитектуры дата-центра не позволяет перенаправлять IP-адреса между серверами: IP-адрес жестко привязан к серверу, для которого выдан. Если просто назначить IP на интерфейс другого сервера — устройства коммутации не примут запросы и как итог — использование IP-адреса будет невозможным.
Такое решение защищает других клиентов от кражи IP-адреса и не позволяет использовать его нигде, кроме как на сервере, для которого он приобретен. О том, как мы решили эту проблему, я расскажу далее.
Прежде всего нужно было определиться с общей концепцией внедрения одного IP-адреса для разных узлов и разобраться с проблемой, связанной с дизайном сети дата-центра.
Не будем углубляться в устройство ВМ и настройки Proxmox — они не влияют на реализацию. Расскажу только о том, как была устроена сеть клиента до внедрения, для понимания общей картины.
Дизайн сети на стороне клиента до внедрения
Каждый сервер имел (и имеет) по два физических сетевых интерфейса. Первый — для соединения с внешней сетью, второй — для организации локальной сети между серверами кластера. Локальная сеть реализована на базе нашей стандартной услуги VLAN.
Сеть в кластере была реализована на основе EVPN+VXLAN. Такой подход позволял объединять виртуальные машины всего кластера в общую сеть с единой адресацией, которая работала поверх VLAN. То есть все ВМ находились в одной виртуальной сети, независимо от их расположения на физических серверах.
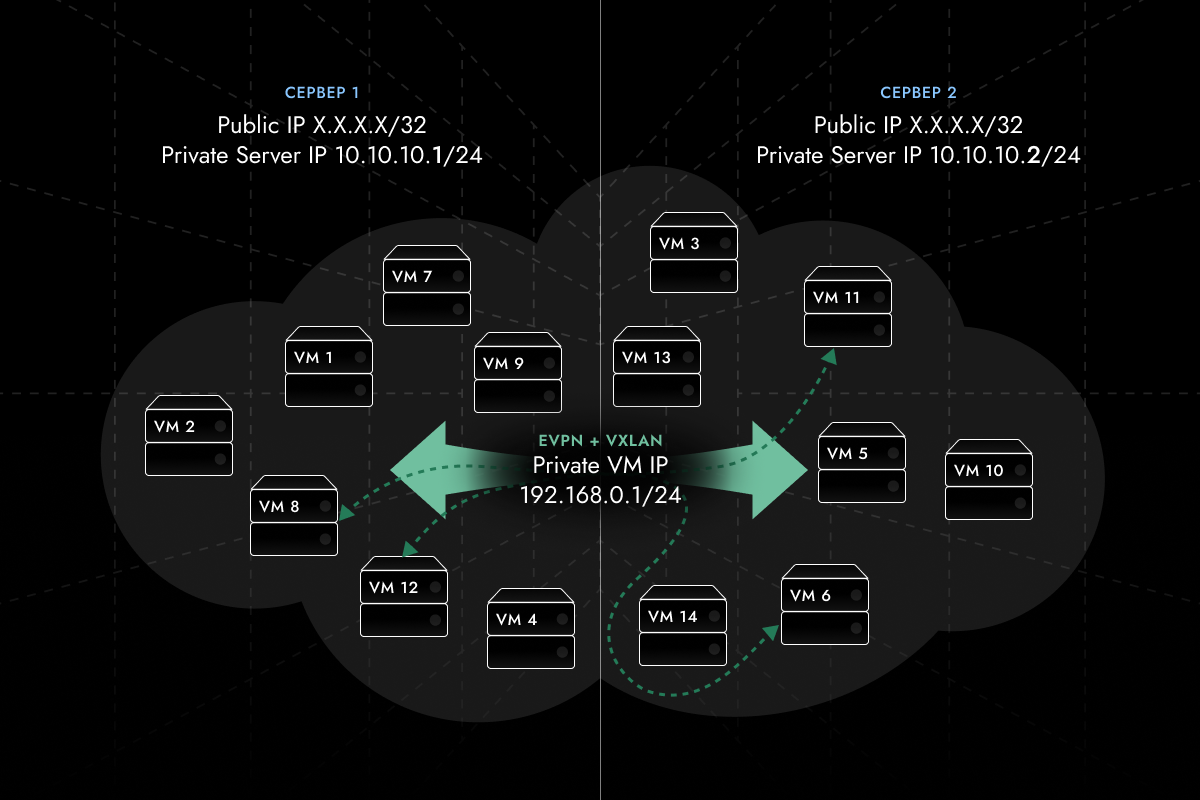
На виртуальных машинах размещались сервисы — условно фронтенд и бэкенд. О чем мы уже говорили выше. При этом сервисы фронтенда для связи с интернетом использовали IP-адреса с защитой от DDoS-атак. На момент обращения клиента эти сервисы не дублировались: их недоступность напрямую влияла на работоспособность проекта.
Что мы решили изменить
Для фронтенда были нужны защищённые IP, но использовать их для всей инфраструктуры избыточно. Поэтому мы решили задействовать только два сервера из четырёх, распределив по ним виртуальные машины с сервисами фронтенда. Основная идея заключалась в том, что экземпляры одного и того же сервиса размещаются на разных физических хостах, что страхует их на случай сбоя сервера.
Так при внедрении такого подхода мы получили бы:
Как я уже говорил, сетевая архитектура дата-центра по умолчанию не позволяет нам использовать один IP-адрес на нескольких серверах. Для решения этой «проблемы» мы решили использовать схему BGP+FRR.
Грамотный читатель может возразить, что такое решение не имеет отношения к плавающим IP. Это действительно так. Технически наша реализация работает не так, как плавающие IP. В связке BGP+FRR узлы будут одновременно анонсировать IP-префиксы, то есть адрес будет доступен с каждого узла. А для плавающего IP справедливо сказать, что в момент времени он доступен только с одного узла. Мы решили использовать связку BGP+FRR, так как она хорошо ложится на сетевой дизайн дата-центра и, по сути, идеально решает нашу задачу.
На нашем хостинге управление IP-адресами осуществляется на сетевом оборудовании дата-центра. Суть нашего решения — анонсировать необходимый пул IP-адресов не стандартным образом, а непосредственно с конечных устройств, чтобы обойти жёсткую привязку IP к конкретному серверу и получить возможность перемещать IP между узлами.
И здесь у нас было два варианта:
Этот вариант проще в реализации и не требует дополнительных настроек на стороне виртуальной машины. Однако есть большой минус — адрес будет переключаться в момент сбоя всего физического хоста, а не конкретной виртуальной машины.
Этот вариант, напротив, позволяет нам настроить работу схемы более точечно. И основанием для переключения будет выступать именно недоступность виртуальной машины. При таком подходе реализация становится более гибкой и позволяет дублировать каждый сервис, а не только физический узел.
Как итог: мы получаем возможность распределения трафика между несколькими узлами. По сути, мы можем создать связку из двух одинаковых виртуальных машин на разных физических хостах и перемещать IP между ними. И таких «связок» может быть сколько угодно (для любого из сервисов своя). Каждая связка может использовать как один, так и несколько IP-адресов.
Таким образом, мы остановились на варианте с анонсом от виртуальной машины. Вот какая схема получилась.
Схема анонса для внедрения у клиента
Используя связку BGP+FRR, мы, по сути, анонсируем IP-префикс одновременно с нескольких узлов. И фактически сетевые роутеры дата-центра (которые занимаются маршрутизацией трафика) видят оба анонсируемых префикса.
Для того чтобы роутеры понимали, какой из префиксов использовать для отправки трафика — используется атрибут MED (Multi‑Exit Discriminator). Это атрибут анонсируемого префикса, который задает его приоритет. Атрибут задается вручную в экспортной политике, на узле, который анонсирует префикс. Чем меньше значение MED сервер передает для своего префикса, тем выше приоритет его выбора вышестоящими роутерами. То есть роутеры будут использовать тот анонс, что имеет самое меньшее значение атрибута MED.
Если по какой-то причине роутеры перестали получать ответ устройства, инициирующего префикс с самым низким MED, то они переключатся на префикс, у которого в этот момент самое низкое значение MED.
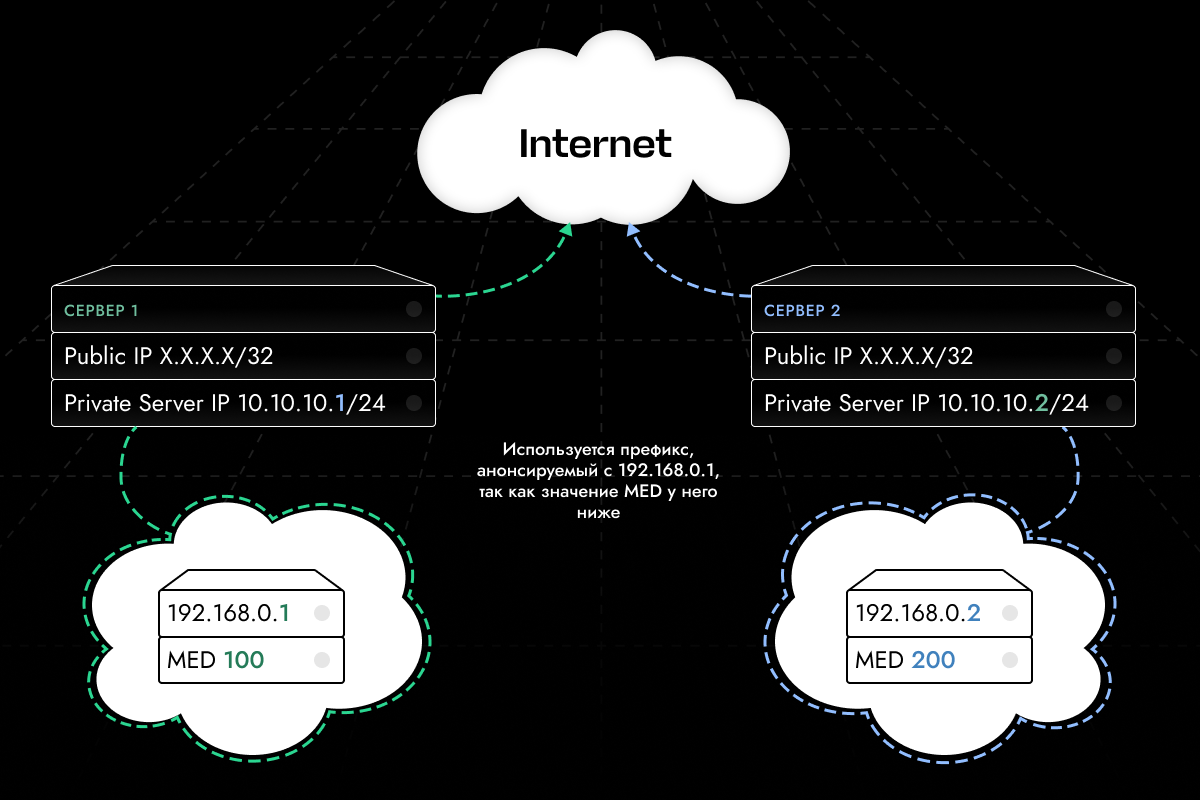
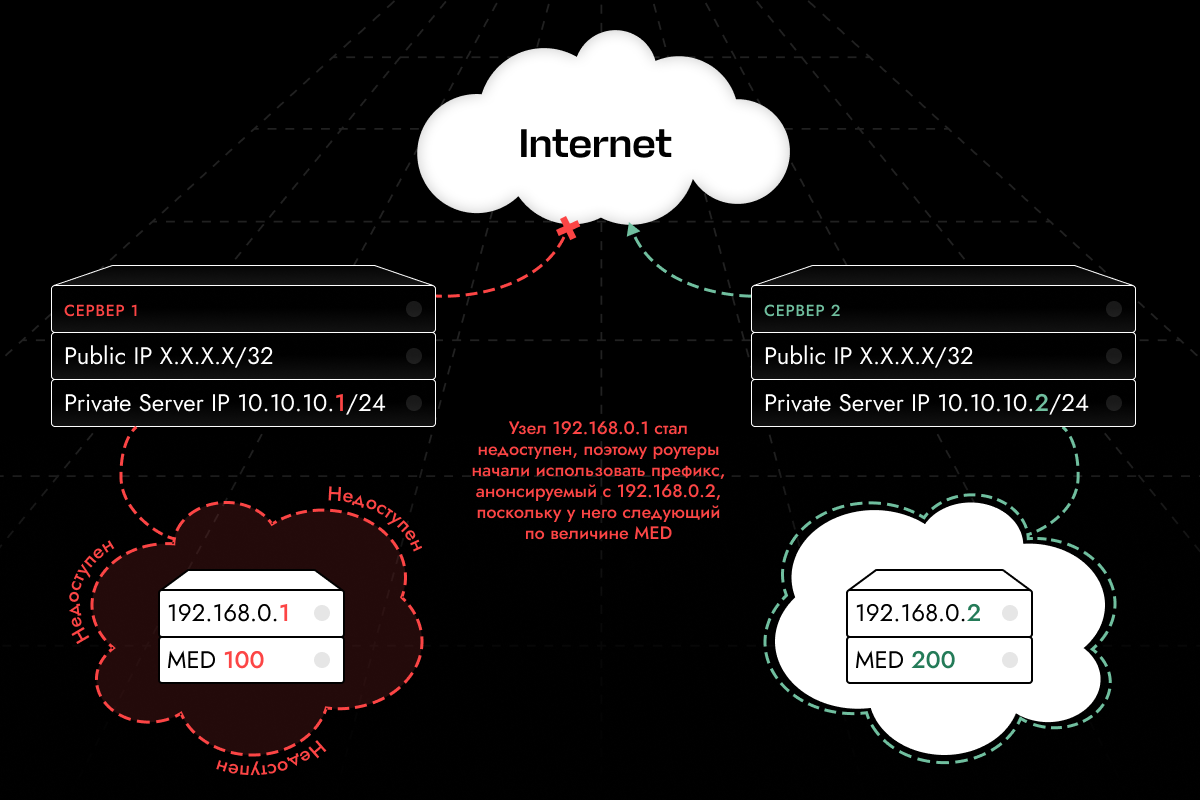
Для корректной работы с конечного узла (виртуальной машины) мы анонсируем префикс с нужными правилами до физического хоста. Физический хост, в свою очередь, будет реанонсировать префикс непосредственно на роутеры дата-центра.
Существуют и другие сценарии использования связки BGP+FRR. Например, балансировка адреса или распределение трафика между узлами. Однако нашему клиенту это не требовалось. Перед нами не стояла задача настройки конечных сервисов, эту задачу на себя взял клиент. Нам было важно обеспечить только переключение адреса в случае возникновения проблемы.
Для того чтобы анонсирование IP-префиксов с серверов вообще стало возможно, нам требовалось подключить услугу Анонс сетей (BGP anycast). Услуга позволила бы нам анонсировать префиксы напрямую с сервера/серверов, «забирая» эту задачу у маршрутизирующего оборудования дата-центра.
При внедрении связки BGP+FRR мы также решили пересмотреть сетевой стек, а именно — отказаться от использования EVPN+VXLAN и вернуться к схеме с классическим Linux Bridge.
По нашему мнению, на таком уровне инфраструктуры EVPN+VXLAN только усложняет сетевой стек, добавляя дополнительный уровень инкапсуляции и маршрутизации. Также при внедрении FRR для анонса, наличие EVPN создаст больше путаницы с маршрутами и конфигурациями.
Итого, мы рассчитывали получить вот такой сетевой стек проекта после внедрения:
Совместно с клиентом мы разработали поэтапный план работ и согласовали время. Сначала провели подготовку на тестовом стенде — это помогло отработать схему без риска и оценить сроки. Затем приступили к реализации на боевой инфраструктуре. Рассмотрим подробнее каждый этап.
Перед тем, как внедрять готовое решение на уровне клиентской инфраструктуры, мы воспроизвели все действия на тестовом стенде, чтобы отработать и отладить при необходимости весь процесс. Для этого организовали тестовый контур из двух физических серверов и привели его в конфигурацию, аналогичную клиентской.
Такой подход помог нам выработать общий план, замерить время на прохождение каждого этапа и на основе этого подготовить первичную документацию по реализации.
Чтобы мы могли анонсировать префиксы, нужно было для каждого сервера активировать услугу Анонс сетей (BGP anycast) и настроить FRR на уровне физического сервера. Без этого сетевое оборудование дата-центра не принимает анонсы от сервера. Также мы переделали логику работы сети на Linux Bridge (об этом писал ранее).
Выполняли работы по очереди: сначала для первого сервера, затем для второго. Простой каждого сервера — до 30 минут. На время настройки сервер терял связность с интернетом.
После того как анонс стал возможен, мы сначала протестировали его работу на тестовых виртуальных машинах, чтобы не затрагивать боевые сервисы. Для этого развернули по одной тестовой ВМ на каждом из двух серверов, установили и настроили на них FRR. Затем имитировали сбой на ВМ, которая анонсировала префикс — отключили на ней FRR. Префикс первой ВМ пропал, но роутеры сразу стали использовать анонсируемый префикс второй ВМ, что подтвердило работоспособность решения.
Этап никак не повлиял на работу сервисов клиента и не подразумевал их простоя.
Так как анонсирование префиксов выполняется напрямую с виртуальной машины — нужно было установить и настроить FRR на каждой из них. Также нужно было добавить новые адреса на стороне Proxmox, чтобы Cloud‑Init (инструмент автоматической настройки ВМ) знал о них и использовал.
При настройке каждая ВМ временно теряла доступность — в среднем около двух минут на ВМ. Технически можно было обойтись без простоя, но мы специально выполняли рестарт виртуальных машин, так как хотели убедиться, что после их перезапуска новые адреса назначаются корректно.
Этот этап занял продолжительное время, так как сервисы переводили на новую схему постепенно.
На этом настройку и внедрение реализации можно считать завершенными.
Также в процессе внедрения мы провели ряд сопутствующих работ:
Кроме того, провели миграцию ВМ в рамках кластера и выполнили ряд других работ, которые к реализации относились лишь косвенно, поэтому на них подробно не останавливаемся.
Ниже — примеры конфигов FRR, которые адаптировали для кейса, с комментариями по основным моментам. Они помогут вам понять логику настройки и при желании адаптировать под свои задачи.
Конфиги приведены как образец, не используйте их без изменения!
В конфиге приведен вариант с двумя анонсируемыми адреса и четыремя виртуальными машинами, которые будут инициировать BGP-сессии.
frr version 10.2.2
frr defaults traditional
hostname node-name.example.local ! ← Укажите хостнейм своего сервера (например, имя сервера или гипервизора)
log syslog informational
no ipv6 forwarding
service integrated-vtysh-config
! ← Список адресов для анонса. Если адрес не указан, фильтр не пропустит его анонс.
! ← При добавлении новых адресов увеличивайте seq: 5, 10, 15 и т.д.
ip prefix-list PREF_ISP seq 5 permit X.X.X.X/32 ! ← Вместо X.X.X.X/32 укажите IP-префикс который будет анонсироваться
ip prefix-list PREF_ISP seq 10 permit XY.XY.XY.XY/32 ! ← Вместо XY.XY.XY.XY/32 укажите IP-префикс который будет анонсироваться
route-map EXPORT_POLICY permit 10
match ip address prefix-list PREF_ISP
set community none
set origin igp
exit
router bgp 65534 ! ← Укажите номер используемой AS. Либо используйте из пула приватных (от 64512 до 65534)
bgp router-id Y.Y.Y.Y ! ← Вместо Y.Y.Y.Y укажите внешний (публичный) IP сервера
no bgp enforce-first-as
bgp always-compare-med
! ← Вместо указанных адресов добавьте адреса виртуальных машин, которые будут анонсировать IP. Замените номер используемой AS на свой.
neighbor 192.168.0.11 remote-as 65534
neighbor 192.168.0.12 remote-as 65534
neighbor 192.168.0.21 remote-as 65534
neighbor 192.168.0.22 remote-as 65534
! ← В этом блоке указываются BGP‑пиры провайдера, для установки с ним eBGP‑сессии. Данные уточняйте у провайдера
neighbor Z.Z.Z.Z remote-as 0000000000
neighbor Z.Z.Z.Z ebgp-multihop
neighbor Z.Z.Z.Z ttl-security 2
address-family ipv4 unicast
! ← Список правил работы с маршрутами каждого участника. Здесь указываем всех соседей (виртуальные машины которые инициируют сессии)
neighbor 192.168.0.11 soft-reconfiguration inbound
neighbor 192.168.0.11 route-map EXPORT_POLICY in
neighbor 192.168.0.12 soft-reconfiguration inbound
neighbor 192.168.0.12 route-map EXPORT_POLICY in
neighbor 192.168.0.21 soft-reconfiguration inbound
neighbor 192.168.0.21 route-map EXPORT_POLICY in
neighbor 192.168.0.22 soft-reconfiguration inbound
neighbor 192.168.0.22 route-map EXPORT_POLICY in
! ← В этом блоке указываются правила взаимодействия с провайдером.
neighbor Z.Z.Z.Z route-reflector-client
neighbor Z.Z.Z.Z soft-reconfiguration inbound
neighbor Z.Z.Z.Z route-map EXPORT_POLICY out
neighbor Z.Z.Z.Z next-hop-self force
neighbor Z.Z.Z.Z attribute-unchanged med
exit-address-family
exitВ примере конфига FRR виртуальной машины будет анонсировать все IP-префиксы, что имеются у виртуальной машины.
Несколько узлов могут анонсировать один префикс. В таком случае приоритет будет выбора узла будет осуществляться через значение атрибута set metric (MED). Также один узел может анонсировать сразу несколько префиксов.
frr version 8.4.4
frr defaults traditional
hostname vm-192-168-0-11.local ! ← Укажите хостнейм виртуальной машины
log syslog informational
no ipv6 forwarding
service integrated-vtysh-config
!
route-map BLOCK_IN deny 10 ! ← Блокировка входящих маршрутов от других соседей, чтобы не принимать чужие маршруты.
exit
!
route-map EXPORT_POLICY permit 10
! priority metric
set metric 300 ! ← Данное значение задает приоритет анонса (MED). Если адрес анонсируют несколько устройств, то по умолчанию будет использоваться анонс с самым низким значением.
exit
!
router bgp 65534 ! ← Укажите номер используемой AS (должна быть та же, что и у хоста).
bgp router-id 192.168.0.11 ! ← Укажите IP виртуальной машины
neighbor 10.10.10.1 remote-as 65534 ! ← Укажите IP хоста и номер используемой AS
!
address-family ipv4 unicast
redistribute connected
redistribute static
! ← Список правил работы с маршрутами хоста
neighbor 10.10.10.1 route-map BLOCK_IN in
neighbor 10.10.10.1 route-map EXPORT_POLICY out
exit-address-family
exitКлиент получил возможность использовать IP-адреса на разных узлах. Это позволило сохранить существующую схему взаимодействия с контрагентами и повысить отказоустойчивость сервисов. Мы со своей стороны, помимо настройки реализации, осуществляем её мониторинг и контроль 24/7/365.
В этой статье я рассказал только один из возможных вариантов реализации. Важно понимать: подобные задачи решаются индивидуально и требуют предварительного согласования.
Если у вас есть похожая задача или проект, которому требуется постоянное техническое сопровождение, будем рады помочь. Оставить заявку можно здесь.
А для читателей этого кейса мы дарим скидку 30% на первый месяц, при заказе услуги сопровождения. Для получения скидки сообщите в заявке, что прочитали наш кейс, и мы применим её. Подробнее о скидке здесь.